
In this section we, in turn, overview all the types of agents identified in our typology of the previous section bar smart agents. Figure 2 summarises these types and lists the order in which they are surveyed. In particular, we would overview them in terms of some or all of following: their essential metaphors, hypotheses/goals, motivations, roles, prototypical examples, potential benefits, key challenges, and some other general issues about the particular agent type. We do not overview the shaded type, smart agents, on the grounds that this is the aspiration of agent researchers rather than the reality.
As shown in Figure 1, collaborative agents emphasise autonomy and cooperation (with other agents) in order to perform tasks for their owners. They may learn, but this aspect is not typically a major emphasis of their operation. In order to have a coordinated set up of collaborative agents, they may have to negotiate in order to reach mutually acceptable agreements on some matters. Most of the work classified in this paper as strand 1 (see Section 2) investigated this class of agents. As noted earlier, some AI researchers are providing stronger definitions to such agents, e.g. some attribute mentalistic notions such as beliefs, desires and intentions - yielding BDI-type collaborative agents. Hence, the class of collaborative agents may itself be perceived as a broad church.
In brief the key general characteristics of these agents include autonomy, social ability, responsiveness and proactiveness. Hence, they are (or should/would be) able to act rationally and autonomously in open and time-constrained multi-agent environments. They tend to be static, large coarse-grained agents. They may be benevolent, rational, truthful, some combination of these or neither. Typically, most currently implemented collaborative agents do not perform any complex learning, though they may or may not perform limited parametric or rote learning.
The hypothesis, rationale or goal for having collaborative agent systems is a specification of the goal of DAI as noted in Huhns & Singh (1994). Paraphrasing these authors, it may be stated as ëcreating a system that interconnects separately developed collaborative agents, thus enabling the ensemble to function beyond the capabilities of any of its membersí. Formally,
where V represents ëvalue addednessí. This could have an arbitrary definition involving attributes such as speed, worst-case performance, reliability, adaptability, accuracy or some combination of these.
The motivation for having collaborative agent systems may include one or several of the following (they are a specialisation of the motivations for DAI):
The Pleiades project at CMU directed by Tom Mitchell and Katia Sycara has, as one of its objectives, to investigate methods for automated negotiation among collaborative 1 agents, in order to improve their robustness, effectiveness, scalability and maintainability (see http: URL1). The project applies collaborative agents in the domain of Organisational Decision Making over the "InfoSphere" (which refers essentially to a collection of internet-based heterogeneous resources). This infosphere is ripe for the application of these class of agents not least because it is inherently a distributed set of on-line information sources.
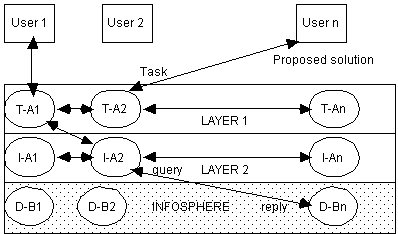
Pleiades is a distributed collaborative agent-based architecture which has two layers of abstraction: the first layer which contains task-specific collaborative agents and second layer which contains information-specific collaborative agents (see Figure 3). This architecture was used to develop the visitor hosting system which was described briefly earlier. Task-specific agents, depicted as task-assistants (T-A) in the figure, perform a particular task for its user, e.g. arranging appointments and meetings with other task-specific agents. These agents coordinate and schedule plans based on the context. They collaborate with one another (at level 1) in order to resolve conflicts or integrate information. In order to garner the information required at this level, they request information from information-specific agents, depicted as information assistants (I-A) in Figure 3. Information-specific agents, in turn, may collaborate with one another (i.e. within layer 2) in order to provide the information requested back to the layer 1 requesting agent. The source of the information are the many databases (D-B) in the infosphere. Ultimately, the task agent proposes a solution (sometimes an intermediate one) to its user.
Task-specific agents have the following knowledge (Sycara, 1995): a model of the task domain, knowledge of how to perform the task, knowledge of how to gather the information for the task, knowledge of other task-specific or information-specific agents it must coordinate with in order to meet the task, protocols that enable coordination with other agents and, lastly, strategies for conflict resolution and information fusion. They also possess some learning mechanisms, e.g. when an agent needs to learn the preferences of its user. On the contrary, information-specific agents know of the following: knowledge of the databases that it is associated with (in addition to details such as their size, average time it takes to answer a query and monetary costs for query processing), knowledge of how to access the databases, knowledge of how to resolve conflicts and information fusion strategies, and protocols for coordination with other relevant software agents. These agents are also ësmartí enough to cache answers to frequently asked queries, and can also induce database regularities which they use during inter-agent interactions.
The main rationale of the architecture is to provide software agents for retrieving, filtering and fusing information from distributed, multi-modal sources and that the agents should assist in decision making. Sycara and her colleagues hypothesised that in order to meet their goals, they would need a distributed collection of collaborative agents which can gather, filter and fuse information in addition to being able to learn from their interactions. Agents communicate using KQML (Finin & Wiederhold, 1991) and e-mail, and they negotiate in order to reach agreements in cases of conflicts. The layered architecture is clearly very modular, indeed modular enough for Sycara and her colleagues to have introduced connectionist modules in the design of other systems.
Clearly, there is much sophistication to this architecture even though we have left out much more interesting details (e.g. how and what the agents learn). Individually, an agent consists of a planning module linked to its local beliefs and facts database. It also has a local scheduler, a coordination module and an execution monitor. Thus, agents can instanstiate task plans, coordinate these plans with other agents and schedule/monitor the execution of its local actions. Interestingly, the architecture has no central planner and hence agents must all engage in coordination by communicating to others their constraints, expectations and other relevant information.
The Pleiades architecture shows clearly how collaborative agents can operate in concert such that their ensemble functions beyond the capabilities of any individual agent in the set-up.
Apart from the visitor hosting system, other systems have also been developed using this architecture/methodology in the domains of financial portfolio management, emergency medical care and electronic commerce (Sycara, 1995). In addition to these domains, there are others ripe for exploiting collaborative agents including workflow management, network management and control, telecommunication networks and business process engineering. In all these domains, collaborative agents may provide much ëadded valueí to current single agent-based applications.
There are many other useful pieces of work on collaborative agents. The first important point to re-emphasise is the fact that much work classified in this paper as strand 1 work (see Section 2) exploited collaborative, deliberative agents; they may not have been fully collaborative as defined in this paper, but they were in spirit. For example, each agent in Durfee et al.ís (1987) distributed vehicle monitoring system (DVMT) is a blackboard knowledge source whose task is to identify the vehicleís track from acoustic data. Each of these agents shared a global knowledge of the problem solving; hence, they are, strictly speaking, not that autonomous and cooperation is quite basic as it all proceeds via the common blackboard. Certainly, other strand 1 testbeds such as MACE (Gasser et al., 1987), MCS (Doran et al., 1990) and IPEM (Ambros-Ingerson & Steel, 1988) have deliberative agents with planning modules that underpin the coordination and cooperation in the set-ups they are operating within. In the case of IPEM and MCS, non-linear planners are used. Other planning-based prototypes include Hayes-Rothís (1991) GUARDIAN architecture and Cohenís et al.ís PHOENIX system. At BT Labs, two prototype collaborative agent-based systems have been developed recently: the ADEPT and MII prototypes. ADEPT (OíBrien & Wiegand, 1996) employs collaborative agents in the application area of business process re-engineering while MII (Titmuss et al., 1996) demonstrates that collaborative agents can be used to perform decentralised management and control of consumer electronics, typically PDAs or PCs integrated with services provided by the network operator.
As regards collaborative agents with much stronger definitions, mention has earlier been made of Rao & Georgeffís characterisation of rational agents in terms of the mental attitudes of beliefs, desires and intentions (Rao & Georgeff, 1992). These are the attitudes typical of epistemic logics. Such work on stronger definitions of collaborative agents is much in progress. Another useful piece of research which attributes mentalistic notions to collaborative agent-based system design is Shohamís (1993) work on agent-oriented programming. In this work, an agentís mental state is described by its beliefs, decisions, capabilities and obligations, and Shohamís language introduces epistemic and deontic modal operators for such notions. This is because in order for agents to reason about these mentalistic attitudes, logics and operators for describing them must be developed. Other agent frameworks based on such mentalistic attitudes include Bratman et al.ís (1988) IRMA and Jenningsí (1993) GRATE/GRATE* environments. Much of the latter work exploits Cohen & Levesqueís (1990) classic work.
The key criticism of collaborative agents levelled by some researchers stems from their grounding in the deliberative thinking paradigm which has dominated AI research over the last thirty years. Some researchers, particularly those in the reactive agents camp, believe that intelligent behaviour can be generated without the sort of explicit symbolic-level representations (and hence, reasoning) prevalent in AI (e.g. Brooks, 1991b). That is, they object to agents having an internal representation of actions, goals and events required by the planning module to determine the sequence of actions that will achieve the goals. Researchers like Agre & Chapman (1987) have challenged the usefulness of having elaborate plans; they argue that a rational, goal-directed activity need not be organised as a plan. They concede that people use plans, but they argue that in real life there is much moment-to-moment improvisation with any plan, which is dependent on the ësituationí of the relevant agent in its physical and social world. Clearly, though this criticism is targeted at the entire deliberative school of AI, it also impacts on deliberative, collaborative agents of whatever complexion. Hence, they contend that such deliberative agents would result in brittle and inflexible demonstrators with slow response times. This viewpoint led to birth of the reactive agents paradigm based on situated-action theory discussed later.
As regards stronger collaborative agent definitions (e.g. BDI agents), Rao & Georgeff (1995) acknowledge the two main criticisms levelled at such work as theirs and Bratman et al.ís (1988). First, while traditional planning researchers and classical decision theorists question the necessity for having all of these epistemic attitudes (i.e. beliefs, desires, intentions), DAI researchers with a sociological bias question why they only have three! Secondly, the logics underpinning these agents, mostly second-order modal logics, have not been investigated fully and their relevance in practice is questionable. Rao & Georgeff (1995) tackle both these issues in their paper. Indeed, they proceed to describe how BDI agents, with some simplifying assumptions to their theoretical framework, are being applied to large-scale applications - in this case, OASIS, an air-traffic management application prototype which has been successfully tested at Sydney airport in 1995. This prototype has been tested with 100+ aircraft agents and 10+ global agents which handle other issues including windfields, trajectories and coordination (Georgeff, 1996). Full implementation is already in progress. However, it must be emphasised that research into such stronger definition of agents, relatively, is still very much in its infancy.
Some more ëcriticismsí of collaborative agents are presented next as challenges still to be addressed by collaborative agent researchers.
Despite successful demonstrators like the Pleiades system and MII (Titmuss et al., 1996), these agents have been deployed in none but a few real industrial settings though this situation is changing, e.g. those built under the auspices of the ARCHON project (Wittig, 1992; Jennings et. al., 1993) or a couple of others built with the involvement of Mike Georgeff, e.g. the Space Shuttle Malfunction Handling system and the agent-based Royal Australian Airforce Simulator (Georgeff, 1996). There are still many teething problems; we mention several here. Note that these are not necessarily specific to collaborative agents only:
In conclusion, despite the criticisms of collaborative agents by those within and without other agent camps, there are many industrial applications which would benefit significantly from them, in just the same way as there are applications which would benefit from reactive agents. For example, at BT, we see a potential major role for them in managing telecommunications networks and in business process management (Nwana, 1996).
Interface agents (c.f. Figure 1) emphasise autonomy and learning in order to perform tasks for their owners. Pattie Maes, a key proponent of this class of agents, points out that the key metaphor underlying interface agents is that of a personal assistant who is collaborating with the user in the same work environment. Note the subtle emphasis and distinction between collaborating with the user and collaborating with other agents as is the case with collaborative agents. Collaborating with a user may not require an explicit agent communication language as one required when collaborating with other agents.
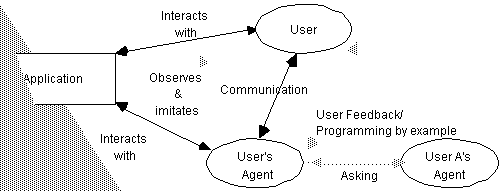
Figure 4 depicts the functioning of interface agents. Essentially, interface agents support and provide assistance, typically to a user learning to use a particular application such as a spreadsheet or an operating system. The userís agent observes and monitors the actions taken by the user in the interface (i.e. ëwatches over the shoulder of its userí), learns new ëshort-cutsí, and suggests better ways of doing the task. Thus, the userís agent acts as an autonomous personal assistant which cooperates with the user in accomplishing some task in the application. As for learning, interface agents learn typically to better assist its user in four ways (Maes, 1994) all shown in Figure 4:
Their cooperation with other agents, if any, is limited typically to asking for advice, and not in getting into protracted negotiation deals with them as is the case with collaborative agents. The learning modes are typically by rote (memory-based learning) or parametric, though other techniques such as evolutionary learning are also being introduced. In summary a learning interface agent,
"as opposed to any kind of agent, is one that uses machine-learning techniques to present a pseudo "intelligent" user interface for its actions" (Foner, 1993, p. 1).
The objective of interface agents research (as Maes sees it) is to work towards Alan Kayís dream of having indirectly managed human-computer interfaces (Kay, 1990). The argument goes as follows. Current computer user interfaces only respond to direct manipulation, i.e. the computer is passive and always waits to execute highly specified instructions from the user. It provides little or no proactive help for complex tasks or for carrying out actions such as searches for information that may take an indefinite time (Maes, 1995). In the future, there will be millions of untrained users attempting to make use of computers and networks of tomorrow. Therefore, instead of a user issuing direct commands to some interface, he could be engaged in cooperative process in which human and software agents can both initiate communication, perform tasks and monitor events. This cooperation between human and agent would benefit the human in using this application.
Hence, the goal is to migrate from the direct manipulation metaphor to one that delegates some of the tasks to (proactive and helpful) software interface agents in order to accommodate novice users. The hypothesis is that these agents can be trusted to perform competently some tasks delegated to them by their users. More specifically, that
"under certain conditions, an interface agent can "program itself" (i.e., it can acquire the knowledge it needs to assist its user). The agent is given a minimum of background knowledge, and it learns appropriate "behavior" from the user and from other agents" (Maes, 1994, p. 89).
She goes on to explain that two preconditions need to be fulfilled by suitable application domains: firstly, that there is substantial repetitive behaviour in using the application (otherwise, the learning agent will not be able to learn anything) and, secondly, that this repetitive behaviour is potentially different for different users (otherwise, use a knowledge-based approach).
To recap, an interface agent is a quasi-smart piece of software which assists a user when interacting with one or more computer applications. Therefore, the motivating, underlying principle of interface agents seems to be that there is no inherent merit in drudgery. Where boring and laborious tasks (particularly, but not exclusively at the user interface) could be delegated to interface agents, they should be - in order to eliminate the tedium of humans performing several manual sub-operations say. A motivating reason for the choice of domains that Maesí group has tackled has been their dissatisfaction with the ways that tasks in these domains are handled currently. For example, she explains that valuable hours are wasted managing junk mail, scheduling and rescheduling meetings, searching for information among heaps of it, etc. - indeed, the title of her 1994 paper captures succinctly her motivation: ëAgents that Reduce Work and Information Overloadí (Maes, 1994).
The general benefits of interface agents are threefold. First, they make less work for the end user and application developer. Secondly, the agent can adapt, over time, to its userís preferences and habits. Finally, know-how among the different users in the community may be shared (e.g. when agents learn from their peers). Perhaps these will be understood better by discussing some of the roles for which Maes and her team at MIT are building interface agents. Thus far, her team has constructed demonstrator agents for the following roles:
We overview them briefly.
Kozierok & Maes (1993) describe an interface agent, Calendar Agent, for scheduling meetings which is attachable to any application provided it is scriptable and recordable, e.g. scheduling software package. Calendar Agent assists (i.e. its role is in assisting) its user in scheduling meetings which involves accepting, rejecting, scheduling, negotiating and rescheduling meeting times. It really comes into its element because it can learn, over time, the preferences and commitments of its user, e.g. she does not like to attend meetings on Friday afternoons, he prefers meetings in the morning, etc. The learning techniques employed are memory-based learning and reinforcement learning.
Liebermann (1995) describes an agent called Letizia (a keyword and heuristic-based search agent) which assists in web browsing. Letiziaís role is that of a guide. When users operate their favourite browser, e.g. Netscape, they must state their interests explicitly when using traditional search engines such as Webcrawler or Lycos. The user remains idle while the search is in progress, and likewise, the search engine is idle whilst the user is browsing the interface. Essentially, Letizia provides a cooperative search between itself and the user. Since most browsers encourage depth-first browsing, Letizia conducts a breadth-first search concurrently for other useful locations that the user may be interested in. It does this by ëguessingí the userís intention and proceeding to search using the search engine. It guesses the userís intentions via inferring from his/her browsing behaviour, e.g. she keeps returning to some particular page, you enter a page into your hotlist or you download some article. The userís actions immediately refocus the search. By doing this, it is able to recommend some other useful serendipitous locations.
The Remembrance Agent (Rhodes & Starner, 1996) is attached currently to an Emacs editor. As the user composes some e-mail message, say, the agent is able to carry out a keyword search and retrieve the five most relevant e-mails in her directory relating to this e-mail being composed. It is really successful when it recommends continuously and unobstrusively invaluable documents, e-mails or files which you would otherwise have forgotten when, for example, you are composing some new document. It can also be used, conceivably when browsing the web or writing a paper; in the latter case, the remembrance agent may recommend other researchersí papers which should be consulted. Hence, its role is clearly that of a memory aid.
Sheth & Maes (1993) and Maes (1994) describe a news filtering agent, called NewT, whose role is that of helping the user filter and select articles from a continuous stream of Usenet Netnews. The idea is to have the user create one or many "news agents" (e.g. one agent for sports news, one for financial news, etc.) and train them by example (i.e. by presenting to them positive and negative examples of what should/or should not be retrieved). It is message-content, keyword-based but it also exploits other information such as the author and source. NewT is even more complicated because a userís population of information filtering agents evolve with time using genetic computing techniques. Indeed, some similar new work at MIT is investigating agents that ëbreedí in their environment, i.e. information agents, given feedback on the information returned, breeds progressively more of those which return ëgood qualityí information, and purges the rest that do not (see Moukas, 1996).
Foner (1996) reports on his Yenta/Yenta-lite matchmaking agent prototype whose goals scenarios include being able to match buyers and sellers of some item and introducing them to one another, finding and grouping people with compatible professional or personal interests, or building coalitions of people interested in the same topics. Each user in the community has a Yenta agent. Yenta agents are able to carry out referrals which work in the same fashion as word-of-mouth recommendations used by people daily. Yenta deals currently with text such as electronic mail messages, the contents of a userís files in a directory, etc. For example, two users, A and B, are deemed to share the same interest if A has at least one granule of interest as B. A granule may represent the fact that a user reads regularly newsgroups on politics say. Matchmaking presents some challenging problems which are covered in Fonerís paper.
Chavez & Maes (1996) describe some preliminary ideas on Kasbah, a classified ads service on the WWW that incorporates interface agents. Kasbah is meant to represent a ëmarket placeí (a web site) where Kasbah agents, acting on behalf of their owners, can filter through the ads and find those that their users may be interested in, and then proceed to negotiate, buy and sell items. Kasbah-like agents may, in the future, render middlemen or brokers redundant.
Last, but by no means least, is the entertainment selection agent which Maes believes has the best potential of all her application domains to be the next "killer application". For example, the Ringo/HOMR system (Shardanand & Maes, 1995; Maes, 1995a) is a personalised recommendation system for music albums and artists, which exploits interface agents. These agents work by social filtering, i.e. a userís agent finds other agents which are correlated, and recommends whatever films their users like to its own user. Hence, like Yenta agents, Ringoís working is similar to a word-of-mouth approach. Maes (1995b) also describes the ALIVE system which is
"a virtual environment which allows wireless full-body interaction between a human participant and a virtual world which is inhabited by autonomous agents", p. 112.
However, it presents a much more challenging illustration of how autonomous interface agents may be used in entertainment. Essentially, ALIVE demonstrates how agents can form a link between animated characters, based of Artificial Life models, and the entertainment industry.
We hope it is clear that the potential for these interface agents are large. All these demonstrators have been or are being evaluated with users and the results so far are, in the main, quite promising. For example, Ringo has been used by more than 2000 people (Shardanand & Maes, 1995).
In order to emphasise that the distinction between some of these agent types is quite fuzzy, Lashkari et al.ís (1994) paper on collaborative interface agents presents a framework for multi-agent collaboration, and discuss results of a demonstrator based on interface agents for electronic mail. This paper emphasises cooperation between agents more than typical interface agents do.
Less, the reader gets the impression that interface agents research only proceeds in Maesí group at MIT, we must state that this is certainly not the case. We have been biased towards them because we (i.e. BT) have ready access to and close links with Pattie Maes and her work and/or demonstrators. Other work on interface agents include Dent et al. (1992) and Hermens & Schlimmer (1993). Dent et al. (1992), for example, describe a personal learning apprentice agent research done at CMU. This Calendar APprentice agent (CAP), like Kozierok & Maesí (1993) Calendar Agent, assists the user in managing and scheduling its meetings. Their philosophies are essentially the same and the key difference is in their use of learning techniques: Dent et al.ís apprentice uses back-propagation neural network and decision tree learning techniques while Calendar Agent (Kozierok & Maes, 1993) uses memory-based and reinforcement learning. Mitchell et al. (1994) summarise results from five user-years of experience over which CAP has learned and evolved a set of several thousand rules that model the scheduling preferences of each of its users. These rules could be augmented or edited by users. Hermens & Schlimmer (1993) and Lang (1995) also describe other learning apprentice interface agents. What may differentiate these agents are their performances.
The key criticism of interface agents is that, so far, they tend to function in stand-alone fashions or, at the most, only engage in restricted and task-specific communication with identical peers (Lashkari et al., 1994), which is why the latter authors have begun addressing this issue. This is not necessarily bad but it would be useful to have interface agents being able to negotiate with their peers as do collaborative agents. Furthermore, as Mitchell et al. (1994) note
"...it remains to be demonstrated that knowledge learned by systems like CAP can be used to significantly reduce their usersí workload" (p. 90).
But this is the key motivation for having interface agents in the first place (Maes, 1994). Moreover, Wayner & Joch (1995, p. 95) cite Bob Balaban, a systems architect at Lotus Notes, who argues apparently that most people do not need a smart agent which can look over their shoulders, guess their desires and, proactively, take action. He is quoted as saying "I know exactly what I want", arguing he does not need an agent to try to learn from his behaviour. This viewpoint may be dismissed outright by interface agent researchers, but Balabanís point remains - do people want/need interface agents? It appears it is not a forgone conclusion that they do. It may just be another working hypothesis!
Following on from the last section, some challenges for interface agents include:
However, having stated these, there is no denying the fact that interface agents can/will be deployed in real applications in the short term because they are simple, operate in limited domains and do not, in general, require cooperation with other agents.
Mobile agents are computational software processes capable of roaming wide area networks (WANs) such as the WWW, interacting with foreign hosts, gathering information on behalf of its owner and coming ëback homeí having performed the duties set by its user. These duties may range from a flight reservation to managing a telecommunications network. However, mobility is neither a necessary nor sufficient condition for agenthood. Mobile agents are agents because they are autonomous and they cooperate, albeit differently to collaborative agents. For example, they may cooperate or communicate by one agent making the location of some of its internal objects and methods known to other agents. By doing this, an agent exchanges data or information with other agents without necessarily giving all its information away. This is an important point, not least because the public perception of agents (thanks to the popular computing press) is almost synonymous with mobile agents. For example, Peter Waynerís (1995b) agent text (and there are almost no other agent texts about currently) is titled ëAgents Unleashed: A Public Domain Look at Agent Technologyí, but it is all about mobile agents. Whilst the ëunleashedí in the title gives it away, it is rather subtle - so, Wayner could be accused of reinforcing this rather jaundiced view, that agents equals mobile pieces of software.
Another myth to slay is that mobile agents equals Telescript, the current leading mobile agent operating environment invented at General Magic (Mountain View, CA). Through some very clever marketing, General Magic has managed to put mobile agents ëon the mapí and link their name simultaneously and inextricably to it. But other mobile agent demonstrators or applications not based on Telescript do exist.
The key hypothesis underlying mobile agents is that agents need not be stationary; indeed, the idea is that there are significant benefits to be accrued, in certain applications, by eschewing static agents in favour of their mobile counterparts. These benefits are largely non-functional, i.e. we could do without mobile agents, and only have static ones but the costs of such a move are high. For example, consider the scenario borrowed from Wayner (1995b) where the user is required to write a program that would allow her home computer make a flight reservation for her by accessing several airline reservation databases. She lists all her preferences: non-smoking, departure between 7 and 9.30 am from Baltimore, arrival at Austin before noon, no more than one connection, and no changes at Chicago OíHare. A static single-agent program would need to request for all flights leaving between these times from all the databases, which may total more than 200 and take up many kilobytes. It would also require a list of all the connections and proceed to narrow down the search. Each of these actions involves sifting through plenty of extraneous information which could/would clog up the network. Besides, she is probably paying for this network time.
Consider the alternative. She encapsulates, object-oriented style, her entire program within an agent which consumes probably less than 2K which roams the network of airline reservation systems, arrive safely and queries these databases locally, and returns ultimately to her home computer, with a schedule which she may confirm or refute. This alternative obviates the high communications costs of shifting, possibly, kilobytes of information to her local computer - which presumably she cannot cope with. Hence, mobile agents provide a number of practical, though non-functional, advantages which escape their static counterparts. So their motivation include the following anticipated benefits.
Telescript is an interpreted object-oriented and remote programming language which allows for the development of distributed applications (see http: URL2). The interpreter and runtime development environment for the Telescript language is called the Telescript engine and a given host can support simultaneously multiple Telescript engines. Figure 5 summarises a part view of the Telescript architecture. It shows just one of these Telescript engines integrated onto an operating system via a programming interface called the Telescript application programmer interface (API). The Telescript Development Environment (TDE) can now be downloaded freely from URL2 and it comprises the engine, browser, cloud manager, debugger and associated libraries.
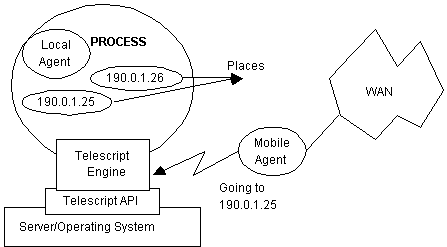
Telescript applications consist of Telescript agents operating within a ëworldí or cyberspace of places, engines, clouds and regions. All of these are objects. For example, a place is an instance of some class within the engine whose definition inherits operations which can be called on that place. The top class in Telescriptís object hierarchy is the process. A Telescript engine is itself a multitasking interpreter which can run multiple processes and switches preemptively between them. Hence, the engine can host multiple agents that share data/information between themselves. Furthermore, a place is itself a process which can contain an arbitrary number and depth of other places. Figure 5 also shows a local agent process. Agent processes, unlike place processes, are objects which cannot contain other processes, but they can ëgoí from place to place (note that places have unique network addresses as shown in Figure 5). An agent requiring a service defined at some given place must go to that place and call the operations there (cf. Figure 5).
So to effect remote programming, Telescript makes use of these three language concepts: places, agents and "go". "Go" is the primitive which allows for inter-process communication. Two or more agent processes can meet (in one place using the meet command) and make use of each otherís services. They do this by setting up a communication channel - this is the basis for cooperation. Indeed, by agents moving places, they can exploit the services implemented at these places.
A "go" requires a destination space and the host engine packages up the agent along with all its data, stack and instruction pointer and ships it off to its destination place which may be across a vast WAN. At its destination, the other Telescript-enabled engine unpacks it, checks its authentication, and it is then free to execute at its new place. When it finishes, it returns to its original host having performed the task required by its owner. Non-cooperation occurs when a place refuses to accept an incoming agent process. In the free market model, services would be located at places, and it is up to the agent processes to ëgoí there, ënegotiateí for the services, use them, pay and return to their owners.
Mobile agent applications do not currently abound but are likely to increase to be in the short to medium term, especially after General Magicís release of their Telescript Development Environment into the public domain with their Open Telescript Initiative. However, the first commercial application was Sonyís Magic Link PDA or personal intelligent communicator (PIC) (see http: URL3). Essentially, it assists in managing a userís e-mail, fax, phone and pager as well as linking the user to Telescript-enabled messaging and communication services such as America Online and AT&T PersonaLink Services. The latter, for example, can carry text, graphics and sound. Magic Link operates through the Magic Cap software platform, and a Magic Cap user can send executable agents (Telescript processes) via e-mail through the network. Hence, if two or more users connect their Sonyís Magik Link PDAs to AT&Tís PersonaLink services (which supports Magic Capís e-mail messaging), it provides a platform for an application which could exploit email-based Telescript mobile agents.
Plu (1995) mentions that France Telecom, who are a member of the General Magic Alliance and therefore had access to Telescript technology, has prototyped some services based on Telescript. In one of their demonstrators, they have used mobile Telescript agents to integrate railway ticketing and car renting services, and the prototype is able to propose an optimal solution depending on price and time. As noted in Section 3, IBM plans to launch their ICS system which uses mobile agents for providing a communications super-service: capable of routeing and translating communications from one service and medium to another, e.g. mobile to desktop, PDA to fax, speech to text, etc.
As we write, many others applications are in the pipeline. Telescript technology is now also evolving into active web tool technology (see http: URL3).
Telescript is not the only system that permits agents to roam from place to place. In the late 1980s, Siemens developed an application which they called ëIntelligent Moving Processesí (Wolfson et al., 1989). In this work, computer programs are interpreted on one machine until a "move" statement is encountered. A ëmoveí statement causes the packaging of the program, data and instruction pointer (just like with Telescript) and the despatching of this package to a target machine. At the target, a process unpackages the process and the program resumes execution at the new location.
There are other languages which support mobile agent system development notably Java from Sun Microsystems. Java is a programming language similar in syntax to C++, but also similar in other ways to Smalltalk.
It is also important to point out that mobile agent systems need not only be constructed using an agent-oriented system like Telescript. Indeed, Wayner (1995b) shows examples of how mobile agents can be scripted in Xlisp. Other languages to consider include Agent-Tcl, Safe-Tcl and C/C++. Indeed, a couple of years ago at BT Labs, Appleby & Steward (1994) prototyped a mobile agent-based system for controlling telecommunication networks. This system was written completely in C/C++. In this system, there are two types of mobile agents which provide different layers of control in the system. Each node in the network is represented by a routeing table storing the neighbouring node to which traffic should be routed in order for that traffic to reach its particular destination node. The agents control congestion by making alterations to these routeing tables in order to route traffic away from congested nodes. This prototype demonstrated that an ensemble of mobile agents could control congestion in a circuit-switched communications network. In fact, this novel application won the authors a prestigious British Computer Society (BCS) award.
The key criticism of mobile agents is undoubtedly their security. Already, for example, BT Labs operate a ëfirewallí which prevents our internal networks being reached from outside. The thought of allowing mobile agents roam into and out of our networks, however benign they are, send shivers up many spines. Telescript agents cannot write to system memory or to disk and so it is safer than viruses which do. However, you can never be too careful as to what roaming agents may leave behind. Furthermore, the range of applications based on mobile agents are rather few, even though this situation will almost certainly have changed by the time this paper is published.
Wayner (1995a) lists the major challenges. They include the following. As usual, they are not exhaustive.
In addition to these are the following:
Having listed these, it must be noted that some of them are already being addressed successfully in development environments like TDE using various techniques including the following: using ASCII-encoded, Safe-Tcl scripts or MIME-compatible e-mail messages for transportation; using public-key and private-key digital signature technology for authentication, cash and secrecy; and providing limited and/or interpreted languages that will prevent illegal instructions from being executed, for security; for example, environments would typically not allow an agent to write to memory as viruses do. As a result, much software and hardware (e.g. new consumer electronics products) which exploit mobile agent-based services are currently in the pipeline.
Information agents have come about because of the sheer demand for tools to help us manage the explosive growth of information we are experiencing currently, and which we will continue to experience henceforth. Information agents perform the role of managing, manipulating or collating information from many distributed sources.
However, before we proceed, perhaps we should clarify that there is, yet again, a rather fine distinction, if any, between information agents and some of those which we have earlier classed as interface or collaborative agents. For example, in Section 5.1.3, we saw the presence of ëinformation-specificí collaborative agents in the Pleiades distributed architecture (see Figure 3). In Section 5.2.3, we described briefly Sheth & Maesí news filtering agent, NewT, which helps filter and select articles from a continuous stream of Usenet Netnews. We also discussed briefly the Letizia search agent and the remembrance agent. We would not attempt to argue with any researcher who would rather class all these agents as information agents. Interface or collaborative agents started out quite distinct, but with the explosion of the WWW and because of their applicability to this vast WAN, there is now a significant degree of overlap. This is inevitable especially since information or internet agents are defined using different criteria. They are defined by what they do, in contrast to collaborative or interface agents which we defined by what they are (i.e. via their attributes, see Figure 1). Many of the interface agents built at the MIT Media Labs, for example, are autonomous and learn, but they have been employed in WWW-based roles; hence, they are, in a sense, information agents. This is a rather subtle distinction, but it must be clarified.
"We are drowning in information but starved of knowledge" (John Naisbitt, Megatrends).
Similarly, vis-à-vis the WWW, it is also the case that we are drowning in data but starved of information. The underlying hypothesis of information agents is that, somehow, they can ameliorate, but certainly not eliminate, this specific problem of information overload and the general issue of information management in this information era. We agree with Tom Henry, vice president of SandPoint, who is quoted in Indermaur (1995) as saying that the biggest challenge is to create a simple user interface so that information search and retrieval using information agents will become as natural for people as picking up a phone or reading a newspaper. Though Henry is quoted in Indermaurís article in the context of ëassistantí agents, we believe this is the ultimate goal for information agents. Your information agents would, perhaps, put together your own personal newspaper, just as you want it. The information agents would have to be endowed with the capabilities of knowing where to look, how to find the information and how to collate it.
The case for having information agents should be clearer from the following. Davies & Weeks (1995) report that in 1982, the volume of scientific, corporate and technical information was doubling every 5 years. Three years later, i.e. 1988, it was doubling every 2.2 years, and by 1992 every 1.6 years. This trend suggests that it should now be doubling every year. What is more, much of this information is now accessible electronically on the WWW, whose phenomenal growth over the last 5 years has astonished most. Nicholas Negroponte, head of MITís Media Labs, claimed in a recent talk at BT Labs that the web was doubling every fifty days. This latter figure is arguable (we believe it is overly optimistic) but the explosive growth of information and the WWW is unquestionable.
The motivation for developing information/internet agents is at least twofold. Firstly, there is simply a yearning need/demand for tools to manage such information explosion. Everyone on the WWW would benefit from them in just the same way as they are benefiting from search facilitators such as Spiders, Lycos or Webcrawlers. As Bob Johnson, an analyst at Dataquest Inc., notes:
"in the future, it [agents] is going to be the only way to search the Internet, because no matter how much better the Internet may be organised, it can't keep pace with the growth in information ...".
Secondly, there are vast financial benefits to be gained. Recall that Netscape Corporation grew from relative obscurity to a billion dollar company almost overnight - and a Netscape or Mosaic client offers generally browsing capabilities, albeit with a few add-ons. Whoever builds the next killer application - the first usable Netscape equivalent of a proactive, dynamic, adaptive and cooperative agent-based WWW information manager - is certain to reap enormous financial rewards. Furthermore, $21 billion was spent by Internet users on purchasing air tickets including hotel bookings, car rentals, etc. in 1995 alone. This compares significantly with the US/European market totals of $170 billion (see http: URL5)
As noted earlier, information agents have varying characteristics: they may be static or mobile; they be non-cooperative or social; and they may or may not learn. Hence, there is no standard mode to their operation.
Internet agents could be mobile, i.e. they may be able to traverse
the WWW, gather information and report what they retrieve to a
home location. However, this is not the norm as yet. Figure 6
depicts how the typical static ones work. It shows how an information
agent, typically within some browser like Netscape, uses a host
of internet management tools such as Spiders and search engines
in order to gather the information. The information agent may
be associated with some particular indexer(s), e.g. a Spider.
A Spider is an indexer able to search the WWW, depth-first, and
store the topology of the WWW in a database management system
(DBMS) and the full index of URLs in the WAIS. Other search/indexing
engines or spiders such as Lycos or Webcrawler can be used similarly
to build up the index. Indeed, there are currently more than twenty
spiders on the WWW.
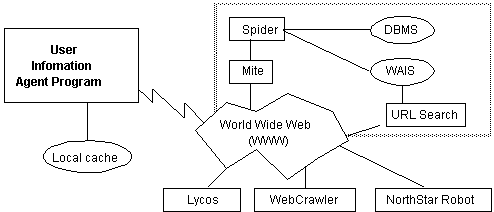
The user information agent, which has been requested to collate information on some subject, issues various search requests to one or several URL search engines to meet the request. Some of this search may even be done locally if it has a local cache. The information is collated and sent back to the user.
Etzioni & Weld (1994) describes a state-of-the-art agent called the internet softbot (software robot). It is a fully implemented agent which allows a user to make a high-level request, and the softbot is able to use search and inference knowledge to determine how to satisfy the request in the internet. In doing so, it is able to tolerate ambiguity, omissions and the inevitable errors in the userís request. In their paper, Etzioni & Weld use a strong analogy to a real robot in order to describe their softbot-based interface to the internet.. For example, they describe the softbotís effectors to include ftp, telnet, mail and numerous file manipulation commands including mv or compress. The sensors provide the softbot with information about the external world and they include internet facilities such as archie, gopher and netfind and other Unix commands such as mv or compress; netfind, for example, is used to determine some userís e-mail address.
The contribution of softbot, in its designersí view, is threefold. Firstly, it provides an integrated and expressive interface to the internet. Secondly, it chooses dynamically which facilities to invoke when and in what sequence. Thirdly, if a UUCP gateway goes down during a search, it is able to backtrack from one facility to another, at run-time in order to try an alternative to meet its goal. This is quite important, not least because the softbot is very goal driven. Prima facie, the softbot presents a menu-based interface through which users can compose queries (users are also allowed to use the first-order logic based notation which supports negation, conjunction, quantification and disjunction, but studies have shown that they are uncomfortable with it). However, at its core, the softbot is a goal-driven planner. It translates the filled-in menu form into a softbot goal which it tries to satisfy. It is therefore able to handle tasks such as "send the budget memos to Mitchell at CMU" and "Get all of Ginsbergís technical reports that arenít stored locally". Clearly, there is much disambiguation for the softbot to do, e.g. in the former, who is exactly the intended recipient of the memos? To do this the softbot has to execute a finger mitchell@cmu.edu, inter alia, to resolve this. In the latter example, the softbot would need to use the ftp utility, but it would also have to find out where to retrieve Ginsbergís papers, which of his papers are not stored locally (using a combination of universal quantification and negation), and, finally, issue ftp commands to retrieve them. In brief, the planner is the core module which is able to decompose a complex goal expression into simpler ones and go on to solve them. It resolves issues such as interactions between subgoals which it also detects automatically.
Softbots may be implemented for a host of other problems including filtering e-mails, scheduling meetings and performing system maintenance tasks. We classed the softbot as an information agent rather than as an interface agent because learning is not the crucial feature of it, though it does some limited memory-based learning. For example, returning to an example given earlier, the softbot is able to record for future reference that it is now familiar with all the Mitchells at CMU - hence, obviating the need to carry out a disambiguation process next time a similar query is received.
We expect information agents to be a major growth area in the next couple of years. At BT Labs, Davies & Weeks (1995) have designed and implemented the Jasper agent - Jasper is an acronym for Joint Access to Stored Pages with Easy Retrieval. Jasper agents work on behalf of a user or a community of users, and is able to store, retrieve, summarise and inform other agents of information useful to them found on the WWW. As a user works with his Jasper agent, a profile of his interests is built dynamically based on keywords. In effect, a Jasper agent is able to ësit at the side of a userí and suggest interesting WWW pages. Its suggestions are based on a set of keywords given by the user and other ëinterestingí WWW pages suggested by other users in the community. These pages are then summarised and keywords are extracted from them which are used to index the pages. If another userís keywords match closely some page, the summary of the page and its URL is e-mailed to the particular user.
There are other information agents built in particular for information filtering. For example, Webwatcher (Amstrong et al., 1995), the RBSE Spider (Eichmann, 1994a) and Metacrawler (http: URL4). The last two are strictly speaking not agents, e.g. Metacrawler is certainly a meta-search engine which provides an interface to other search engines on the WWW. A query submitted to it is translated and forwarded to other search engines; it collates the results and returns them to the user. Spiders are not agents because, even though they explore, autonomously, the topology of the web; generally, they neither learn nor collaborate with other spiders, yet.
The key problem with static information agents is in keeping their indexes up-to-date in an environment which is prone to complete chaos. Some researcher such as Etzioni & Weld (1994) and Eichmann (1994a) have also voiced concerns about the ethics of information agents. We return briefly to such ethical issues towards the end of this paper.
It is probable that the majority of future information agents will be of the mobile variety for similar reasons mentioned in Section 5.3. They would be able to navigate the WWW and store its topology, in a database say, at their home site. The local database may then be queried using SQL.
This section is much briefer. As regards the challenges of information agents, we believe that they are essentially either similar to those of interface or mobile agents. If the information agents are static, then most of the challenges of interface agents apply (see Section 5.2.5). However, if they are mobile, then most of the challenges for mobile agents are applicable (see section 5.3.4). Likewise, the criticisms of information agents are similar to those of interface and mobile agents depending on whether they are static or mobile respectively.
Reactive agents represent a special category of agents which do not possess internal, symbolic models of their environments; instead they act/respond in a stimulus-response manner to the present state of the environment in which they are embedded. Reactive agents work dates back to research such as Brooks (1986) and Agre & Chapman (1987), but many theories, architectures and languages for these sorts of agents have been developed since. However, a most important point of note with reactive agents are not these (i.e. languages, theories or architectures), but the fact that the agents are relatively simple and they interact with other agents in basic ways. Nevertheless, complex patterns of behaviour emerge from these interactions when the ensemble of agents is viewed globally.
Maes (1991a, p. 1) highlights the three key ideas which underpin reactive agents. Firstly, ëemergent functionalityí which we have already mentioned, i.e. the dynamics of the interaction leads to the emergent complexity. Hence, there is no a priori specification (or plan) of the behaviour of the set-up of reactive agents. Secondly, is that of ëtask decompositioní: a reactive agent is viewed as a collection of modules which operate autonomously and are responsible for specific tasks (e.g. sensing, motor control, computations, etc.). Communication between the modules is minimised and of quite a low-level nature. No global model exists within any of the agents and, hence, the global behaviour has to emerge. Thirdly, reactive agents tend to operate on representations which are close to raw sensor data, in contrast to the high-level symbolic representations that abound in the other types of agents discussed so far.
The essential hypothesis of reactive agent-based systems is a specification of the physical grounding hypothesis, not to be confused with the physical symbol system hypothesis. Traditional AI has staked most of its bets on the latter which holds that the necessary and sufficient condition for a physical system to demonstrate intelligent action is that it be a physical symbol system. On the contrary, the physical grounding hypothesis challenges this long-held view arguing it is flawed fundamentally, and that it imposes severe limitations on symbolic AI-based systems. This new hypothesis states that in order to build a system that is intelligent, it is necessary to have representations grounded in the physical world (Brooks, 1991a). This hypothesis is quite radical and it turns, literally, the physical symbol system hypothesis ëon its headí. Brooks argues that this hypothesis obviates the need for symbolic representations or models because the world becomes its own best model. Furthermore, this model is always kept up-to-date since the system is connected to the world via sensors and/or actuators. Hence, the reactive agents hypothesis may be stated as follows: smart agent systems can be developed from simple agents which do not have internal symbolic models, and whose ësmartnessí derives from the emergent behaviour of the interactions of the various modules.
It is important to note that all current reactive software agents do not necessarily possess actuators and sensors which connect them to the physical world, though Brooks would insist on them. Indeed, in a paper titled ëIntelligence without Robotsí, Etzioni (1993) has argued that software environments
"circumvent many thorny but peripheral research issues that are inescapable in physical environments", p. 7.
However, the essence of the physical grounding hypothesis still holds with such reactive agents: no explicit symbolic representations, no explicit (abstract) symbolic reasoning and an emergent functionality. Reactive agents are simple and easy to understand, and their ëcognitive economyí (Ferber, 1994) is very low; this is because they have to ërememberí little. They are situated, i.e. they do not plan ahead or revise any world models, and their actions depend on what happens at the present moment.
The key benefits which motivates reactive agents work, in addition to the hypothesis mentioned earlier, is the hope that they would be more robust and fault tolerant than other agent-based systems, e.g. an agent may be lost but without any catastrophic effects. Other benefits include flexibility and adaptability in contrast to the inflexibility, slow response times and brittleness of classical AI systems. Another benefit, it is hoped, is that this type of work would address the frame problem (Pylyshyn, 1987) which has so far proved intractable with traditional AI techniques such as nonmonotonic reasoning.
It must be stated that there are a relatively few number of reactive software agent-based applications. Partly, due to this reason, there is no standard mode to their operation; rather, they tend to depend on the reactive agent architecture chosen. We describe briefly two of these architectures below.

Perhaps the most celebrated of them all, is Brookís (1991) subsumption architecture. Though Brookís architecture has been used to implement physical robots (hence tightly connecting perception to action), it could also be exploited in purely reactive software agents. The architecture consists of a set of modules, each of which is described in a subsumption language based on augmented finite state machines (AFSM). An AFSM is triggered into action if its input signal exceeds some threshold, though this is also dependent on the values of suppression and inhibition signals into the AFSM. Note that AFSMs represent the only processing units in the architecture, i.e. there are no symbols as those in classical AI work. The modules are grouped and placed in layers (which work asynchronously) such that modules in a higher level can inhibit those in lower layers (see Figure 7). Each layer has a hard-wired purpose or behaviour, e.g. to avoid obstacles or to enable/control wandering. This architecture has been used to construct, at least, ten mobile robots at MIT. Steels (1990) uses similar agents to Brooksí in order to investigate cooperation between distributed simulated robots using self-organisation.
Arguably, the most basic reactive architecture is that based on situated-action rules which, in turn, derives from some work carried out in by Suchman (1987). Situated action agents act essentially in ways which is ëappropriateí to its situation, where ësituationí refers to a potentially complex combination of internal and external events and states (Connah, 1994). Situated-action ëagentsí have been used in PENGI, a video game designed as part of Agreís doctoral thesis (Agre, 1988), and SONJA (Chapman, 1992). Researchers at Philips research laboratories in Redhill, UK, have implemented a situation-action based language called the RTA programming language (Graham & Wavish, 1991). Indeed, they have used this language to implement characters in computer games which they have since integrated into CD-i titles (Wavish & Graham, 1995). Kaebling & Rosenschein (1991) have proposed another language based on a modal logical formalism, which in turn is based on a paradigm called situated automata. Agents written in this language are compiled into digital circuits which implement the reactive agent system.
In summary, few applications based on reactive software agents exist currently but this situation will change before the millenium. A favourite application area for them seems to be the games or entertainment industry, which of course is a multi-billion pound industry. For example, the Philips researchers are already working on digital video and 3-D graphics-based, reactive agent animations (Wavish & Graham, 1995).
Reactive agent systems can be used to simulate many types of artificial worlds as well as natural phenomena. For example, Ferber (1994) describes how he has used them to simulate ant societies where each ant is modelled as an agent and, a limited ecosystem composed of three kinds of agents: biotapes, shoals of fish and fishermen. As he further explains, reactive agents could make the computer become a "virtual laboratory" where the researcher could modify any experimental parameters and validate his model using both qualitative and quantitative data. Nwana (1993) describes a simulation of children in a playground which was implemented using the Agent Behaviour LanguagE (ABLE), a pre-cursor to RTA (Wavish & Graham, 1994). The ALIVE interactive environment mentioned briefly earlier is is an autonomous system because it employs real sensors in the form of a camera.
Many criticisms can be levelled against reactive software agents and their architectures. Firstly, as already noted, there are too few applications about based on them. Secondly, the scope of their applicability is currently limited, mainly to games and simulations. Even Brooksí robots are yet to deliver useful industrial applications even though we can envisage how they can be exploited in certain applications, e.g. in the toys domain. To be fair, it is still early days for such research: arguably, symbolic AI did not start delivering any useful industrial applications until the late 1970s or early 1980s, i.e. more than two decades after symbolic AI was born. So, there is a clear need to expand the range of languages, theories, architectures and applications for reactive agent-based systems. Thirdly, it is not obvious how to design such systems so that your intended behaviour emerges from the set-up of agents. How many of such agents are required for some application? Currently, since it is not allowable to tell the agents how to achieve some goal, as with genetic algorithms,
"one has to find a ìdynamics", or interaction loop or servo loop, involving the system and the environment which will converge towards the desired goal. The interaction process only comes to a rest (or a fixed pattern) when the goals are achieved" (Maes, 1991b, 50).
This would not only be time-consuming, but it also smacks of ëtrial and errorí with all its attendant problems. Fourthly, how are such systems extended, scaled up or debugged? What happens if the ëenvironmentí is changed? Even Brooks (1991a) acknowledges that such questions are frequently asked of his work and so he attempts to tackle them in this paper. However, we do not find his responses very convincing, yet, and perhaps only more applications would improve the trust in the reactive agent hypothesis. Finally, there is the issue of the entire physical grounding hypothesis. Brooks and other nouvelle AI researchers argue that the physical symbol system hypothesis
"implicitly includes a number of largely unfounded great leaps of faith" (Brooks, 1991a, p. 3).
We hope they did not speak too soon: perhaps, the same applies to the physical grounding hypothesis. Etzioni (1993), amongst others, has already challenged Brooksí assertion that the way to make progress in AI is
"to study intelligence from the bottom up, concentrating on physical systems (e.g. mobile robots), situated in the world, autonomously carrying out tasks of various sorts" (Brooks, 1991c), p. 569.
Furthermore, Maes (1991b) has already pointed out that this situated agents work has some important limitations precisely because
"of their lack of explicit goals and goal-handling capabilities" (p. 50),
requiring the designers of the systems to precompile or hard-wire the action selections. For example, she notes correctly that much effort was expended by the Pengi researchers in analysing the strategies for playing the Pengo game, which were later "hard-wired" into Pengi. Hence, while a planning approach leaves much to the agent, the situated agents approach leaves much to the designers.
Maes (1991b) opted for a more hybrid approach in her agent network architecture. In it she implemented an agent as a set of competence modules, each with STRIPS-like (Fikes & Nilsson, 1971) pre- and post- conditions. Modules also get activated if their activation level (a real value) is exceeded, and this level represents the relevance of the module in some situation. If a module has a higher activation level, it will influence the agentís behaviour more. Modules are linked to one another implicitly via various links, e.g. a successor link occurs if a module X has a post-condition ß, which happens to be the pre-condition of module Y.
This list of criticisms above is not exhaustive but it provides some of the challenges for reactive agent researchers to address. In summary, we see the main challenges to include the following:
Despite these challenges, we would expect more applications to be ëhand-craftedí in the medium term.
So far, we have reviewed five types of agents: collaborative, interface, mobile, internet and reactive agents. The debates as to which of them is ëbetterí are rather academic, and frankly, sterile - and rather too early to get into. Since each type has (or promises) its own strengths and deficiencies, the trick (as always) is to maximise the strengths and minimise the deficiencies of the most relevant technique for your particular purpose. Frequently, one way of doing this is to adopt a hybrid approach, like Maes (1991b), which brought together some of the strengths of both the deliberative and reactive paradigms. Hence, hybrid agents refer to those whose constitution is a combination of two or more agent philosophies within a singular agent. These philosophies include a mobile philosophy, an interface agent philosophy, collaborative agent philosophy, etc.
The key hypothesis for having hybrid agents or architectures is the belief that, for some application, the benefits accrued from having the combination of philosophies within a singular agent is greater than the gains obtained from the same agent based entirely on a singular philosophy. Otherwise having a hybrid agent or architecture is meaningless. Clearly, the motivation is the expectation that this hypothesis would be proved right; the ideal benefits would be the set union of the benefits of the individual philosophies in the hybrid. Consider the obvious case of constructing an agent based on both the collaborative (i.e. deliberative) and reactive philosophies. In such a case the reactive component, which would take precedence over the deliberative one, brings about the following benefits: robustness, faster response times and adaptability. The frame problem is also better ameliorated by the reactive component. The deliberative part of the agent would handle the longer term goal-oriented issues. Typically, such hybrid architectures end up having a layered architecture as is evidenced by Muller et al.ís (1995) InteRRaP, Fergusonís (1992) Touring Machines, and Hayes-Rothís (1991) architectures. We describe them briefly below.
As is the case with reactive agents, there are just but a few hybrid agent architectures. A prototypical example of a hybrid example is Muller et al.ís layered InteRRaP architecture shown in Figure 8 developed at the German Research Centre for AI. It is an architecture that implements a layered approach to agent design.
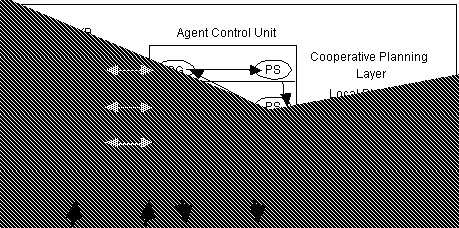
This architecture can be used to construct an agent such as an autonomous robot. As shown, it consists of an agent knowledge base and its associated control unit sitting ëon topí of the perception-action component which also handles the low-level communications. There are three control layers in this architecture: the behaviour-based layer (BBL), the local planning layer (LPL) and the cooperative planning layer (CPL). Clearly, the architecture marries the deliberative and the reactive philosophies. The reactive part of the framework which allows for efficiency, reactivity and robustness are implemented by the BBL which contains a set of patterns of behaviour (PoBs), in effect, situation-action rules. These describe the agents reactive skills which implements fast situation recognition in order to react to time-critical situations. The intermediate LPL implements local goal-directed behaviour while the topmost CPL enables the agent to plan/cooperate with other agents in order to achieve multi-agent plans, as well as resolve conflicts. LPL and CPL allow for more deliberation. These layers all work with different models in the agentís knowledge base: BBL, LPL and CPL operate with the world, mental and social models respectively. Each InteRRaP layer also consists of two processes, SG and PS, which interact with each other as well as with neighbouring layers. These layers work asynchronously. The InteRRaP architecture has been evaluated by constructing a FORKS application which simulates forklift robots working in an automated loading dock environment. For more details on the InteRRaP architecture (whose redesign has been completed recently) and the results of the evaluation, consult Muller et al. (1995), Muller (1994) and Fischer et al. (1996).
Fergusonís (1992a) TouringMachines architecture is another good example of a hybrid "architecture for dynamic, rational and mobile agents" (Ferguson, 1992b), though the word ëmobileí does not refer to mobile agents as in Telescript agents, but to mobile agents as in autonomous robots. This architecture, which is similar to Brookís subsumption architecture (see Figure 7), consists of three control layers: the reactive layer, the planning layer and the modelling layer which all work concurrently. A key distinction between TouringMachines and Brookís subsumption architecture on the one hand, and InteRRaP on the other is that the former are horizontal architectures while the latter is a vertical architecture. This means that all the layers in TouringMachines and the subsumption architecture have access to the perception/sensing data and all the layers can contribute to the actions (as shown in Figure 7), while only the bottom layer in InteRRaP receives and acts on the perceptual data (see Figure 8). Therefore to achieve coordination in TouringMachines, Ferguson has control rules capable of suppressing the input to a certain layer, much similar to the suppression/inhibition mechanisms in the subsumption architecture.
Hayes-Rothís (1995) integrated architecture for intelligent agents consists of two layers: the physical layer which performs perception-action coordination, i.e. it senses, interprets, filters and reacts to the dynamic environment in which the agent is embedded; the cognitive layer receives perceptual input from the physical controller to construct an evolving model, and to perform interpretation, reasoning and planning. Her goal is to provide an architecture for constructing adaptive intelligent agents which can operate in specialised, but challenging, "niches"; indeed, she argues cogently that AI agents must, of necessity, be niche-bound because they are knowledge-bound. The fundamental theoretical concept which underlies her architecture captures succinctly the hybridism that belies it: to construct an agent which "dynamically constructs explicit control plans to guide its choices among situated-triggered behaviors", p. 334. Hence, the physical layer implements reactive situated behaviour while the cognitive layer performs some longer term, deliberative planning and scheduling, drawing from the evolving model. Though the Hayes-Roth (1991) paper was largely a design proposal (aiming to provide sophisticated adaptive, intelligent, versatile and coherent agents), Hayes-Roth (1995) reports that the architecture has not only been implemented, but has also been used to implement several experimental agents. For example, she reports on an agent, Guardian, which has been constructed for one niche - Intensive Care Unit (ICU) monitoring. Guardian is currently able to monitor on the order of twenty continuously sensed patient data variables amongst several other occasionally sensed ones. A new demonstrator, Guardian 5, under development will monitor on the order of a hundred variables. She also reports that she has begun applying the architecture to other niches including Aibots - adaptive intelligent robots. Hayes-Roth et al. (1995) report on an evolving testbed application - an animated improvisational theatre company for children. The idea is to have animated characters (hybrid agents) which can display spontaneous, situated, opportunistic and goal-directed behaviour. The agents collaborate via directed improvisation and the goal is to have the animated characters produce "a joint performance that follows the script and directions in an engaging manner", p. 153.
There are a few other hybrid architectures which we do not review here, an obvious one being the procedural reasoning system (PRS) in which the OASIS prototype (Rao & Georgeff, 1995) mentioned in Section 5.1.4 was implemented. The main reference for PRS is Georgeff & Ingrand (1989). Another hybrid system is CIRCA (Musliner et al., 1993).
Hybrid agent architectures are still relatively few in numbers but the case for having them is overwhelming. There are usually three typical criticisms of hybrid architectures in general, not necessarily the ones reviewed above. Firstly, hybridism usually translates to ad hoc or unprincipled designs with all its attendant problems. Secondly, many hybrid architectures tend to be very application-specific, and for good reasons too. Thirdly, the theory which underpin hybrid systems is not usually specified. Therefore, we see the challenges for hybrid agents research as quite similar to those identified for reactive agents (see Section 5.5.4). In addition to these, we would also expect to see hybrids of other philosophies than reactive/deliberative ones. For example, there is scope for more hybrids within a singular agent: combining the interface agent and mobile agent philosophies which would enable mobile agents to be able to harness features of typical interface agents or some other combination.
Heterogeneous agent systems, unlike hybrid systems described in the preceding section, refers to an integrated set-up of at least two or more agents which belong to two or more different agent classes. A heterogeneous agent system may also contain one or more hybrid agents. As for the other classes, we next discuss their motivation, benefit, how they work, an example and some challenges.
Genesereth & Ketchpel (1994) articulate clearly the motivation for heterogeneous agent systems. The essential argument is that the world abounds with a rich diversity of software products providing a wide range of services for a similarly wide range of domains. Though these programs work in isolation, there is an increasing demand to have them interoperate - hopefully, in such a manner such that they provide ëadded-valueí as an ensemble than they do individually. The hypothesis is that this is plausible. Indeed, a new domain called agent-based software engineering has been invented in order to facilitate the interoperation of miscellaneous software agents. A key requirement for interoperation amongst heterogeneous agents is having an agent communication language (ACL) via which the different software ëagentsí can communicate with each other. The potential benefits for having heterogeneous agent technology are several:
Genesereth & Ketchpel (1994) note that agent-based software engineering is often compared to object-oriented programming in that an agent, like an object, provides a message-based interface to its internal data structures and algorithms. However, they note that there is a key distinction: in object-oriented programming, the meaning of a message may differ from object to object (this is the principle of polymorphism); in agent-based software engineering, agents use a common language with an agent-independent semantics. They highlight three important questions raised by the new agent-oriented software engineering paradigm. They include (p. 48):
In their paper, they begin addressing such issues via ACL - an agent communication language they have been developing as part of a DARPA initiative. ACL, inter alia, consists of the Knowledge Interchange Format (KIF), the Knowledge Query and Manipulation Language (KQML) (Finin & Wiederhold, 1991) and Ontolingua (Gruber, 1991).
To commence, we provide the rather specific definition of the word ëagentí proffered in agent-based software engineering. It defines a software agent as such
"if an only if it communicates correctly in an agent communication language" (Genesereth & Ketchpel, 1994, p. 50).
If new agents are constructed such that they abide by this dictum, then putting them together in a heterogeneous set-up is possible, though not trivial. However, with legacy software, they need to be converted into software agents first. The latter authors note that there are three ways of doing this conversion. Firstly, the legacy software may totally be rewritten to meet the criteria for agenthood - a most costly approach. Secondly, a transducer approach may be used. The transducer is a separate piece of software which receives messages from other agents and translates them into the legacy softwareís native communication protocol, and passes the messages into the program. Likewise, it also translates the programís responses into ACL which is sent on to other agents. This is the favoured approach in many situations where the code may be too delicate to tamper with or is unavailable. Lastly, another approach is the wrapper technique. In this approach, some code is "injected" into the program in order to allow it communicate in ACL. The wrapper can access directly and modify the programís data structures. This is clearly a more interventionist approach which requires the code to be available, but offers greater efficiency than the transduction approach.
Once the agents are available, there are two possible architectures to choose from: one in which all the agents handle their own coordination or another in which groups of agents can rely on special system programs to achieve coordination. The disadvantage of the former is that the communication overhead does not ensure scalability which is a necessary requirement for the future of agents. As a consequence, the latter federated approach (see Figure 9) is preferred typically.

In the above federated set-up, there are five agents distributed in two machines, one with two agents and the other with three. The agents do not communicate directly with one another but do so through intermediaries called facilitators which are similar to Wiederholdís (1992) mediators. Essentially, the agents surrender some of their autonomy to the facilitators who are able to locate other agents on the network capable of providing various services. They also establish the connection across the environments and ensure correct ëconversationí amongst agents. ARCHON (Wittig, 1992) used such an architecture.
PACT is an acronym for Palo Alto Collaborative Testbed which exemplifies the heterogeneous agents approach. It is an interesting experiment which begins to examine
"the technological and sociological issues of building large-scale, distributed concurrent engineering systems. The approach has been to integrate existing multi-tool systems that are themselves frameworks, each developed with no anticipation that they would subsequently be integrated" (Cutkosky et al., 1993).
The prototype they built integrated four legacy concurrent engineering systems into a common framework. More specifically, it involved thirty one agent-based programs executing on fifteen workstations and microcomputers. The agents were organised into a hierarchy based around facilitators (see Figure 9). Agents communicate with other agents via their facilitators. This PACT experiment was also part of the DARPA knowledge sharing effort.
A related area to heterogeneous agent systems is the new discipline of Intelligent and Cooperative Information Systems (ICIS), born in 1992, which seeks to integrate information systems, software engineering, databases and AI by using information agents. Papazoglou et al. (1992) describe such a framework which integrates geographically-dispersed database and knowledge base systems (KBSs). In ICIS, an agent is attached to each database or information system, and thus they behave like their front-ends, i.e. a transduction approach is used. This framework allows for requests for some global piece of information that cuts across these databases and KBSs. The requests need to be decomposed by information agents into sub-requests and disseminated to the appropriate systems and the responses are later collated. Another similar architecture is the Carnot architecture (Huhns et al., 1993) at MCC which is also addressing the problem of logically unifying physically distributed, enterprise-wide, heterogeneous information. The essential component of Carnot agents are the Extensible Service Switches (ESSs) which are the communication aides to the legacy systems. Essentially, ESSs are facilitators which enable both syntactic and semantic communication between the heterogeneous information systems. Unlike in the agent-based software engineering paradigm, there is a global schema to describe the information in the databases. All communication between two information systems, A and B say, is as follows: the query in Aís local context is translated to the global schema which in turn gets translated to Bís local context and vice versa.
The work on heterogeneous agent systems is ongoing and there is a need for methodologies, tools, techniques and standards for achieving such interoperability amongst heterogeneous information sources. The challenges, yet to be met, are captured succinctly in the three questions posed by Genesereth & Ketchpel noted in Section 5.7.1. Such work, as is evidenced in their paper, is already underway.
This concludes our panoramic overview of the different classes of agents identified in Section 4. [an error occurred while processing this directive]